Chữ Việt trong máy tính

Chữ
Việt
trong máy tính:
tiến tới tiêu chuẩn thống nhất
James Đỗ *
Ngày nay, ai muốn dùng Việt ngữ trong máy tính cũng có thể tìm thấy dễ dàng một hệ mềm (software) chuyên dụng, chẳng hạn như để xử lý văn bản hay in ấn. Tuy nhiên, khi đặt ra vấn đề trao đổi thông tin giữa các máy tính và giữa các hệ mềm, hoặc khi muốn xử lý những việc tinh vi hơn, như quản trị cơ sở dữ liệu (data base management), người dùng đứng trước một sự thách đố hầu như không thể vượt qua vì lý do chưa có chuẩn cho chữ Việt trong máy tính. Nếu xét trong phạm vi cả nước thì khó khăn lại tăng gấp bội và trở thành chướng ngại chính trong việc du nhập rộng rãi tin học (informatics), một công cụ hiện đại và thiết yếu để phát triển kinh tế xã hội ở Việt Nam.
Một vài căn bản kỹ thuật
Mỗi kí tự (hay con chữ) nhìn thấy trên màn hình hoặc trên giấy in được mã hoá trong máy tính bằng một con số. Chẳng hạn, trong các máy vi tính ngày nay, con chữ “A” được mã hoá bằng số 65, “B” bằng số 66... “Z” 90 và “a” 97, “b” 98... “z” 122, như đã được qui định bởi chuẩn ASCII của Mỹ (American Standard Code for Information Interchange). Từ đó suy ra, đối với hai máy tính cùng tuân theo ASCII, số 65 sẽ có ý nghĩa chung và duy nhất, là con chữ “A”; chúng có thể trao đổi một cách chính xác loại thông tin viết bằng chữ. Qui trình gán các mã số (code points) cho các con chữ gọi là mã hoá kí tự (character encoding); một tập hợp mã số, kí tự được gọi là một bảng mã (code table).
Bảng mã ASCII sử dụng 7 số nhị nguyên, hay 7 bít, cho phép dùng các mã số từ 0 đến 127 – trong đó các mã số từ 0 đến 31 được dành riêng cho các kí tự điều khiển (control characters), thí dụ số 13 ứng với lệnh xuống dòng; từ 32 đến 126 dành cho các kí tự hiển thị (graphic character). Khi tăng một bít nữa cho mã số, ta có bảng mã 8 bít, cho phép thêm 128 vị trí đủ để mã hoá tất cả các con chữ và dấu thường dùng ở khắp châu Âu. Thực thế, mọi máy vi tính hiện nay dùng các bảng mã 8 bít, có điều là các bảng mã này không thống nhất; thí dụ, kí tự “Á” trong máy Macintosh là số 231, còn trên máy PC-windows là số 193. Thành ra, nếu không có chương trình chuyển mã thích hợp, một hồ sơ văn bản (text file) của máy này đọc trên máy kia sẽ hiện ra như trật chính tả.
Vấn đề mã hoá chữ Việt
Quốc ngữ có 29 con chữ, gồm 12 nguyên âm và 17 phụ âm như sau: a ă â b c d đ e ê g h i k l m n o ô ơ p q r s t u ư v x y. Cộng thêm vào đó là 5 dấu: huyền, hỏi, ngã, sắc, nặng. Mỗi dấu có thể đánh trên một tiếng (âm tiết), và bao giờ cũng đặt ở trên hay dưới nguyên âm. [Ghi chú: việc đánh dấu đúng chỗ có thể tự động hoá được, và đã được Quách Tuấn Ngọc cài đặt tại Đại học Bách khoa Hà Nội, độc lập với (6), xem thêm bài Bỏ dấu ở đâu? trong số này].
Những con chữ như f, i, w, z không có trong quốc ngữ, tuy nhiên vẫn gặp trong các văn bản tiếng Việt. Mỗi con chữ (hoa hay nhỏ) hay mỗi dấu được gọi là một đơn vị chính tả (ĐVCT, orthographic unit). Kết hợp các ĐVCT với nhau thành ra 93 kí tự Việt ngữ (KTVN) – nhỏ – liệt kê dưới đây:
|
a à ả ã á ạ ă ằ ẳ ẵ ắ ặ â ầ ẩ ẫ ấ ậ b c d đ e è ẻ ẽ é ẹ ê ề ể ễ ế ệ f g h i ì ỉ ĩ í ị j k l m n o ò ỏ õ ó ọ ô ồ ổ ỗ ố ộ ơ ờ ở ỡ ớ ợ p q r s t u ù ủ ũ ú ụ ư ừ ử ữ ứ ự v w x y ỳ ỷ ỹ ý ỵ z |
Nhân đôi thành 186 cho cả chữ hoa và chữ nhỏ. Nếu giữ nguyên mã ASCII (128 mã số của bảng mã 7 bít) , và vì 52 KTVN đã có trong ASCII còn lại 134 KTVN phải mã hoá bằng 128 mã số, thành thử phải tìm cách biểu diễn 6 kí tự dôi ra của Việt ngữ. Chính 6 kí tự còn lại này đã là trở ngại chính cho việc chuẩn hoá bộ mã Việt ngữ.
Việc mã hoá ký tự phải đầy đủ (mỗi kí tự trong bộ chữ phải được biểu diễn), tương thích với các chuẩn đã có sẵn trên thế giới, đơn giản và hữu hiệu (một chuỗi kí tự phải được xử lí dễ dàng và minh bạch). Bởi vì chữ viết cho mỗi ngôn ngữ đều là một qui ước thông báo trong đó những đơn vị cơ bản là hình dạng (cho mắt đọc) cho nên qui tắc cơ bản của việc mã hoá kí tự là trước hết phân biệt hình dạng chứ không dựa theo ý nghĩa. Chẳng hạn chữ “d”, tuy có những chức năng và cách phát âm khác nhau giữa tiếng Việt và các tiếng latinh nhưng vẫn chỉ dùng một mã số cho mọi trường hợp. Qui tắc này được sử dụng rộng rãi trong việc mã hoá nhiều chữ viết khác nhau theo hệ chữ ghi ý (ideographics) trong vùng Đông Á (Hán, Kanji, Hanjia, Nôm).
Mã hoá kí tự Việt ngữ và công tác chuẩn
Trên dưới một chục các bộ mã Việt ngữ, thiết kế trong và ngoài nước, có thể được xếp vào bốn loại:
1) Dùng một bảng mã, bỏ rơi 6 KTVN để giữ nguyên mã ASCII và thay thế các KTVN thiếu bằng bằng một KTVN gần nhất; chẳng hạn viết “í” thay cho “ý”. Loại này vi phạm cả những qui luật ngôn ngữ học và qui luật chính tả.
2) Dùng một bảng mã, thay thế 6 kí tự hiển thị của ASCII bằng 6 KTVN. Giải pháp này gây ra nhiều phiền nhiễu cho các công cụ phần mềm có sẵn, thường cần đến tất cả bảng mã ASCII (l).
3) Dùng một bảng mã, thay thế 6 kí tự điều khiển bằng các KTVN. Giải pháp này, trên thực tế, làm biến mất các KTVN đó nhất là trong các hệ mềm không cho phép lẫn lộn kí tự điều khiển và kí tự hiển thị (5).
4) Dùng hai bảng mã khác nhau nhưng đều tương thích ASCII, giữ được tất cả các KTVN, một bảng chữ hoa và một bảng chữ nhỏ. Giải pháp này dẫn đến nhập nhằng vì một mã số có thể biểu thị 2 KTVN khác nhau (5).
Một số hội nghị đã được tổ chức tại Việt Nam trên chủ đề chuẩn hoá việc mã hoá Việt ngữ, cao điểm là hội nghị lần thứ 3 tại thành phố Hồ Chí Minh tháng 7.1988. Nội dung công việc là điểm qua các bảng mã đã có, đề nghị các bảng mã mới để hội nghị phê phán về mặt kĩ thuật, và để cài đặt thử trước khi có thể xác định chuẩn quốc gia. Tháng 9.1991, một hội nghị chuyên đề ở Hà Nội về vấn đề mã hoá Việt ngữ, và về một bộ mã vạn năng đa ngôn ngữ cho máy tính đang thành hình, đã dẫn đến một phương pháp mã hoá bằng 8 bít được đề nghị trở thành chuẩn cho Việt ngữ: mã VSCII (Vietnamese Standard Code for Information Interchange) [Ghi chú: “VSCII” là thuật ngữ do Ngô Thanh Nhàn tạo ra năm 1985, (1)].
Uỷ ban khoa học kĩ thuật nhà nước đã thành lập “Tiểu ban chuẩn hoá mã chữ Việt dùng trong xử lý và trao đổi thông tin trên máy tính” để điều hành công tác VSCII. Tiểu ban này do giáo sư Trần Lưu Chương chủ nhiệm.
VSCII có gì mới?
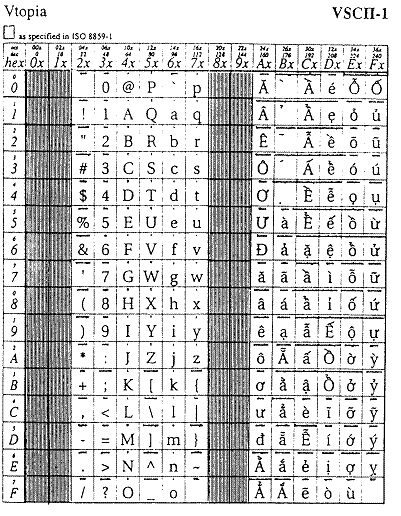
Vì lẽ cả hai giải pháp – 1 bộ mã hoặc 2 bộ mã biệt lập – đều không đạt các yêu cầu kĩ thuật, VSCII là một giải pháp trung dung khả dĩ tồn tại – xây dựng trên cơ sở ngôn ngữ và chính tả Việt Nam – trong đó các đơn vị chính tả và các kí tự Việt ngữ đều được chỉ định trong hai bảng mã (lối thống nhất VSCII-1 và lối pha trộn – VSCII-2). Đặc điểm của giải pháp này là chung cho cả hai bảng mã, mỗi mã số vẫn chỉ định một kí tự duy nhất. Xin xem hai bảng in ở cột bên, kết quả mới nhất của tiểu ban VSCII sau kì họp hè 92.
Mỗi kí tự không dấu được biểu diễn bằng một mã số duy nhất, trong khi đó mỗi kí tự có dấu có thể biểu diễn bằng hai cách:
– hoặc bằng hai mã số liên tiếp, mã của dấu đi theo mã của chữ: thí dụ Ấ = Â’, khi viết như vậy chỉ cần sử dụng bảng
– trong điều kiện cho phép, có thể dùng bảng ASCII-2. Khi đó mỗi kí tự có dấu được biểu diễn bằng một mã số duy nhất.
Nói cách khác các kí tự có dấu có thể biểu diễn bằng hai cách khác nhau trong máy tính. Sự mềm dẻo này cho phép dùng VSCII trong mọi trường hợp, thoát ra ngoài những ràng buộc của các hệ mềm dựa theo chuẩn.
Bảng mã VSCII-1 hoàn toàn thống nhất với ASCII và tuân thủ chặt chẽ những hướng dẫn đặt ra trong nhóm các chuẩn ISO-8859 về việc mã hoá kí tự bằng 8 bít (ISO: International organization for Standardisation, Tổ chức quốc tế về chuẩn hoá, đặt ở Genève). Trong khi đó bảng mã VSCII-2 có đầy đủ các kí tự chính tả mà vẫn giữ các mã số của các kí tự hiển thị ASCII; VSCII-2 được dùng trong các trường hợp trong đó cần thiết chỉ có một mã số cho mọi KTVN, chẳng hạn như để tham chiếu bảng vẽ các con chữ (printer font).
Sau gần một năm xem xét, bàn luận và thử cài đặt, VSCII đã được sửa đổi đôi chút và hiện đang đợi Tổng cục tiêu chuẩn chấp nhận công bố thành một tiêu chuẩn Việt Nam, tiêu chuẩn đầu tiên trong công nghệ thông tin, và cũng là tiêu chuẩn đầu tiên được thiết kế với sự hướng dẫn của ISO.
|
|
|

Sắp tới sẽ ra sao?
Câu chuyện đến đây đã dài, nhưng chưa kết thúc.
Tháng 5.1992, kết hợp hai cố gắng quốc tế của Unicode và ISO, một bộ mã vạn năng – dùng 16 hoặc 32 bít – biểu diễn đa ngôn ngữ trong máy tính được chấp nhận sau khi mọi tổ chức tiêu chuẩn quốc gia trên thế giới đã bỏ phiếu chọn lựa. Chuẩn mới này, dưới tên gọi ISO-10646 hay Unicode 1.1, bao gồm đủ mọi đơn vị chính tả của quốc ngữ. Một đề nghị nữa của Việt Nam – nhằm bao gồm cả việc mã hoá chữ Nôm trong ấn bản tương lai của ISO-10646 – đã được thông qua. Trung Quốc và Triều Tiên bỏ phiếu thuận, trong khi Nhật Bản chống.
Nhiều tiêu chuẩn khác còn thiếu trong công nghệ tin học ở Việt Nam, chẳng hạn như sắp xếp bàn phím và cách đánh máy, tổ chức mạng truyền tin tự động. Tiểu ban VSCII trông cậy vào các chuyên gia ở khắp nơi trong công cuộc hoàn thiện VSCII và các hoạt động khác về chuẩn cho máy tính. Tiểu ban hoan nghênh mọi nhận xét và đóng góp cho nỗ lực chung này.
James ĐỖ
* James Đỗ là một giám đốc về phần mềm của hãng MENTOR GRAPHICS (California, Hoa Kỳ), và cũng là một cố vấn của chương trình TOKTEN của Liên Hiệp Quốc
Bài này nguyên tác bằng tiếng Anh. Vì tác giả không đủ thời giờ chuyển ngữ, nên nhờ Hà Dương Tuấn dịch sang tiếng Việt.
Tài liệu tham khảo:
(l) Centre Informatique, Comité d’Etat pour la Science et la Technologie du Vietnam: Rapport du 3è Symposium national sur la Standardisation du Codage du Jeu des caractères vietnamiens avec signes diacritiques, Hochiminhville 26-30.7.1988.
(2) James Đỗ, Ngô Thanh Nhàn, Nguyễn Hoàng: A proposal for standard Vietnamese characters encoding in a unified text processing framework; Proceedings of the 1rst Unicode Implementers’ workshop, 5-6.8.1991; Computers Standards & Interface 14 (1992), tr.3-32.
(3) Vietnamese Standard Code for Information Interchange (VSCII): Fundamendal Principles, 19.11.1991, Hà Nội.
(4) Dự thảo tiêu chuẩn Víệt Nam VSCII, 20.5.1992, Hà Nội.
(5) Nhóm nghiên cứu tiêu chuẩn tiếng Việt 1: Một khuôn khổ thống nhất cho việc xử lý dữ kiện Việt ngữ; Điện tử & Tin học số 2-1992, tr. 23-25.
(6) Ngô Thanh Nhàn, James Đỗ, Nguyễn Hoàng: Một số kết quả về cách đặt tự động đúng dấu phụ vào chữ Việt; Tạp chí Ngôn Ngữ số 86 (1992), tr. 14-23.
Các thao tác trên Tài liệu









